22 Feb 2021
Horst Rittel and Melvin Webber coined the term’ wicked problems’ in the article ‘Dilemmas in a General Theory of Planning’ (Rittel and Webber, 1973).
Wicked problems are described as;
‘ill-defined, ambitious and associated with strong moral, political and professional issues. Since they are strongly stakeholder dependent, there is often little consensus about what the problem is, let alone how to resolve it. Furthermore, wicked problems won’t keep still: they are sets of complex, interacting issues evolving in a dynamic social context. Often, new forms of wicked problems emerge as a result of trying to understand and solve one of them.’
Rittel and Webber describe the following features of wicked problems in comparison to tame problems.
- There is no definitive formulation of a wicked problem
- Wicked problems have no stopping rule
- Solutions to wicked problems are not true or false, but good or bad
- There is no immediate and no ultimate test of a solution to a wicked problem
- Every solution to a wicked problem is a “one-shot operation”; because there is no opportunity to learn by trial and error, every attempt counts significantly
- Wicked problems do not have an enumerable (or an exhaustively describable) set of potential solutions, nor is there a well-described set of permissible operations that may be incorporated into the plan
- Every wicked problem is essentially unique
- Every wicked problem can be considered to be a symptom of another problem
- The existence of a discrepancy representing a wicked problem can be explained in numerous ways. The choice of explanation determines the nature of the problem’s resolution
- The planner has no right to be wrong
When I look at the common problems associated with DevOps adoption in large organisations;
There isn’t a clear definition of the problem the organisation is trying to solve. DevOps adoption isn’t always tied to a goal or purpose of the organisation. However, sometimes and eventually, the organisation can define the problem they are trying to solve.
2. Wicked problems have no stopping rule
DevOps adoption is an on-going change for large organisations. There rarely is an end-state. There is a failure to recognise that this is on-going continuous change (‘We have transformed’).
3. Solutions to wicked problems are not true or false, but good or bad
Depending on the organisational context, approaches to DevOps adoption differ. What worked for Spotify might not work for a government organisation. However, it’s good enough and works in that context.
Finding a solution to one aspect of adopting DevOps can have repercussions elsewhere. For example, using the Public Cloud creates challenges in the organisation’s approach to governance. Employees find that they need to learn new skills and change their behaviour.
5. Every solution to a wicked problem is a “one-shot operation”; because there is no opportunity to learn by trial and error, every attempt counts significantly
The approach to DevOps adoption is unique to each organisation. I see organisations struggle when they blindly adopt an approach that worked somewhere else. Practitioners also fall into this trap of using a templated approach. The problem has to be solved within a limited timeframe to get a return on investment in DevOps. There is resistance to experimentation and making mistakes.
6. Wicked problems do not have an enumerable (or an exhaustively describable) set of potential solutions, nor is there a well-described set of permissible operations that may be incorporated into the plan
There is no single definitive playbook for DevOps adoption. However, there are specific solutions in the DevOps toolbox to each of the unique problems. The sequence of steps needed to apply the particular solutions in each organisation is unique.
7. Every wicked problem is essentially unique
Each organisation’s approach to adopting DevOps is unique. It’s not repeatable across organisations (it’s not even repeatable within departments inside the same org). The adoption approach has to be reformulated each time. It can’t be planned up-front.
8. Every wicked problem can be considered to be a symptom of another problem
The barriers to DevOps adoption are elsewhere. Recruitment, org structure, culture and lack of diversity, to name a few. The root causes lie outside of the immediate situation of adopting DevOps.
9. The existence of a discrepancy representing a wicked problem can be explained in numerous ways. The choice of explanation determines the nature of the problem’s resolution.
It’s a multi-faceted problem, and people will have various explanations for the problem. Some may not even see it as a problem, and it’s hard to get a single view of the problem.
10. The planner has no right to be wrong
DevOps adoption defies structured planning, yet organisations demand plans. The planner is held to account when ‘DevOps’ still hasn’t been adopted after 6 months. There is no linear path to DevOps adoption.
A paper by the Australian Public Service Commission looking at the public policy challenges to tackling wicked problems (Australian Public Service Commission, 2018) expands on Rittel and Webber’s list of features by adding.
Wicked problems involve changing behaviour. The solutions to many wicked problems involve changing the behaviour and/or gaining the commitment of individual citizens. The range of traditional levers used to influence citizen behaviour—legislation, fines, taxes, other sanctions—is often part of the solution, but these may not be sufficient. More innovative, personalised approaches are likely to be necessary to motivate individuals to actively cooperate in achieving sustained behavioural change.
DevOps adoption, at its core, requires individuals to change their behaviour. For example, developers need to learn how to write tests first and make time for learning. Project managers need to learn how to deal with uncertainty. Senior leadership needs to find out what incentives can be used to motivate individuals to cooperate in achieving sustained behavioural change. Organisations that have previously relied on hierarchy to function have to find new ways to work in a collaborative manner.
Why do I ask?
The reason I ask; Is DevOps adoption a ‘wicked problem’ in large organisations?
If the answer is yes, we must contextualise our approach to DevOps adoption in large organisations. We should also avoid misclassifying the problem as simple or ‘tame’.
Correctly identifying the problem is half the battle, allowing us to use creative and holistic approaches to engage with the situation. It helps to set realistic expectations of change and not go into it blindly with a 14 sprint plan.
References
Australian Public Service Commission (2018) Tackling wicked problems : A public policy perspective, . Australian Government. Available at: https://www.apsc.gov.au/tackling-wicked-problems-public-policy-perspective (Accessed: 21 December 2020).
Rittel, H. W. J. and Webber, M. M. (1973) “Dilemmas in a general theory of planning,” Policy Sciences, 4(2), pp. 155–169. doi: 10.1007/bf01405730.
16 Oct 2019
The first keynote “In defence of Uncertainty” by Abeba Birhane set the tone for the conference. She made the case for why searching for certainty is futile. Ilya Prigogine and Isabelle Stengers in their book Order out of Chaos, say
Traditional science in the Age of the Machine tended to emphasize stability, order, uniformity, and equilibrium. Whereas most of reality, instead of being orderly, stable, and equilibrial, is seething and bubbling with change, disorder, and process.
By using technology we reduce reality, into simpler and manageable pieces. However, this reductive process blinds us to the complex nature of reality. This can and does cause great harm. The systems we build have biases. People are being disadvantaged by technology and they don’t know it.
Our blindfolds of certainty cause more harm than good.
Abeba makes us aware of the harm caused by biased and ill thought out solutions. Examples are Amazon’s AI recruiting tool, a blockchain based app for sexual consent and biased ML software to predict future criminals.
We alter reality with technology - Abeba Brihane
Abeba suggests a different approach.
Its not about the ‘right answers’ but asking meaningful questions
Push more towards understanding and less towards prediction
In place of final, and fixed answers, we aspire for continual negotiation and revision
In place of certainty, we emphasise in-determinability, partial-openness and unfinalizability
Partial-openness leaves room continual dialogue, negotiation, reiteration and revision
The first keynote set the stage for the second keynote “People are the adaptable element of Complex Systems” by John Allspaw. I read Web Operations and the Art Capacity Planning a while back, and it’s interesting to see how John helps the software development community understand Resilience Engineering. At the start of the keynote, he asks;
“If you remove the people keeping systems running, how many systems would keep running?”
Allspaw presents a model which can be used as a lens to look at how we interact with systems
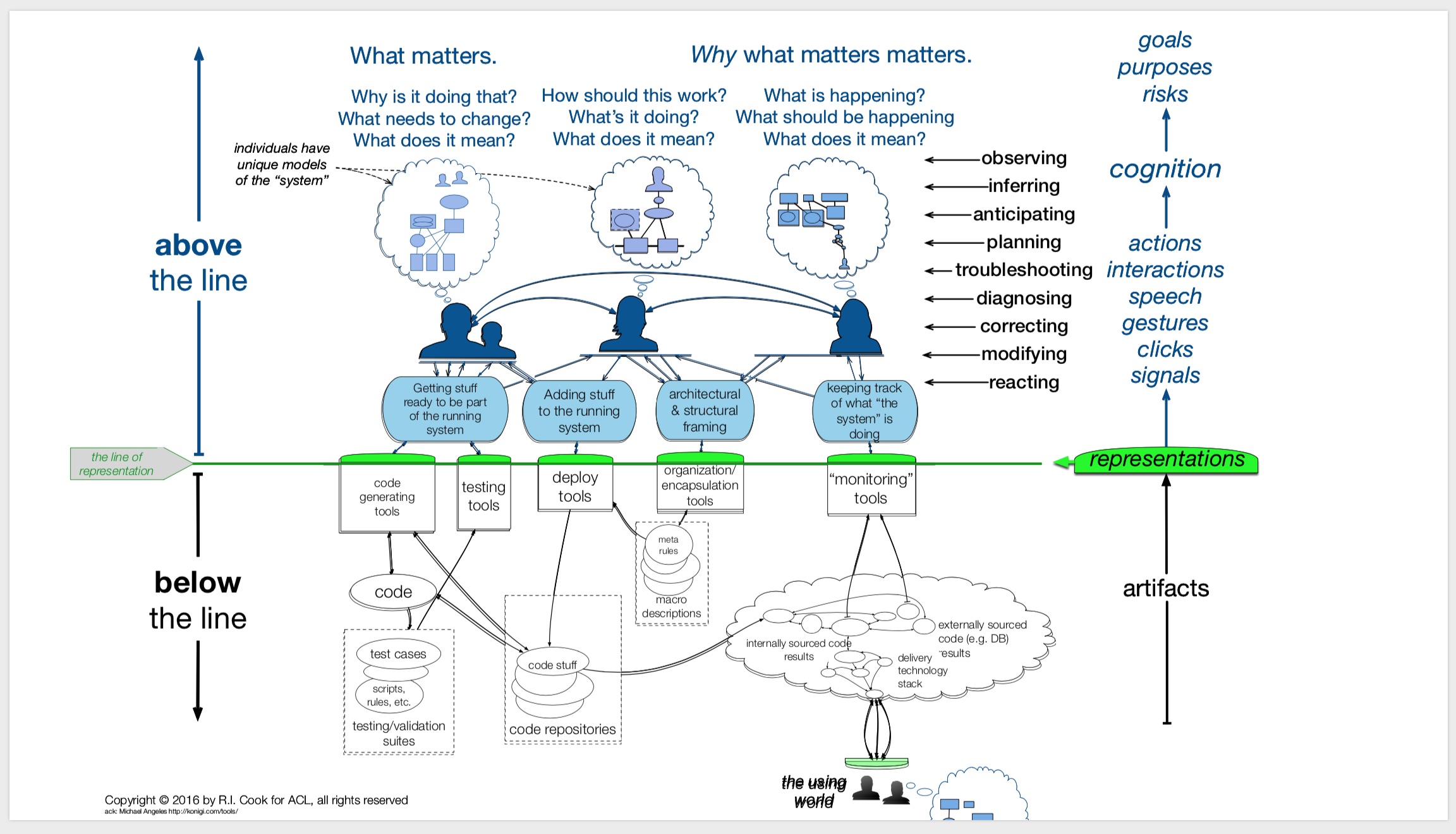
We can use incidents to find out what happens above the line. We need to look deeper into incidents to figure out what happens and how people adapt. Incidents are too complex to be filed under post-mortems. We should learn from incidents. Use incidents as a rich seam of information for research instead of recording incidents to be filed and forgotten.
Magdalena Kiaca and Monica Madrid Costa ran a Visual Faciliation Workshop run by. I’ve been trying to create sketch notes with varying degrees of failure. The workshop helped with a methodical approach.
Attended my first event storming workshop after hearing good things about it from Nick, but this was my first opportunity to see how it’s done by Kenny Baas-Schwegler
Kenny pointed me to a cheat sheet he published.
Finally, Adarsh Shah and I gave a talk on “Using the Toyota Improvement Kata to solve hard problems”
Lean Agile Scotland is going on the annual conference list. Reminds me of attending XP Days London in the early days of my Agile learning.
10 Jun 2019
Any new change to the software we build has risk. To reduce risk, we build quality into our software development process. Automated Tests are a fundamental part of building quality in. We need to build quality in order to go faster. Automated tests are the safety rails that allow us to go faster. Automated tests provide the crucial quick feedback on if we are building it right and if we are building the right thing, as we go faster.
Different types of tests are needed to give fast feedback and we need to maintain the right balance of the different types of tests. Getting this balance right helps get fast feedback, to deliver faster.
For example; Focussing on end to end testing provides the illusion of more value for the effort spent, at the start of a project. But, overtime maintaining end to end tests is a Sisyphean task, diminishing the value we get out of E2E tests.
We are building complex systems. Our tests mirror the systems we build. A simple and singular test strategy will not give us the confidence we need to go fast.
The Testing Pyramid is a visual metaphor to think about testing and the types of tests. This helps us communicate a test strategy. It acts as a guide to getting the balance of the different types of tests right.
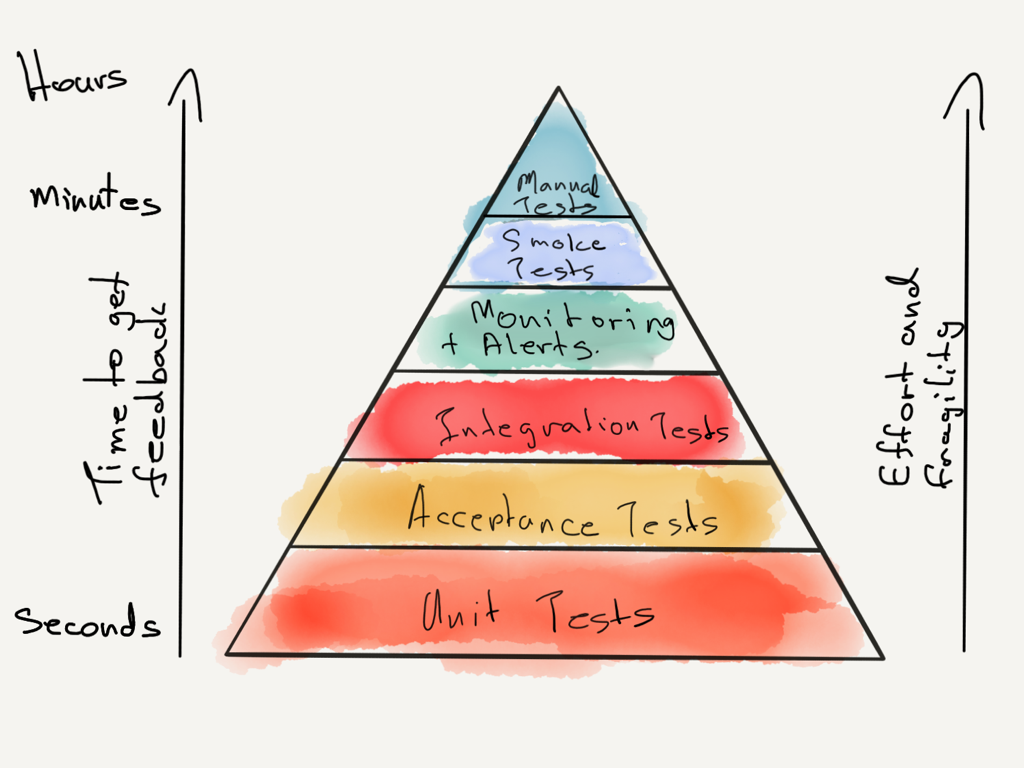
Let’s look at the different types of tests. We’ll look at what each type of test should do. Let’s also look at the effects of focussing on only one type of test and some of the common anti-patterns.
Unit Tests
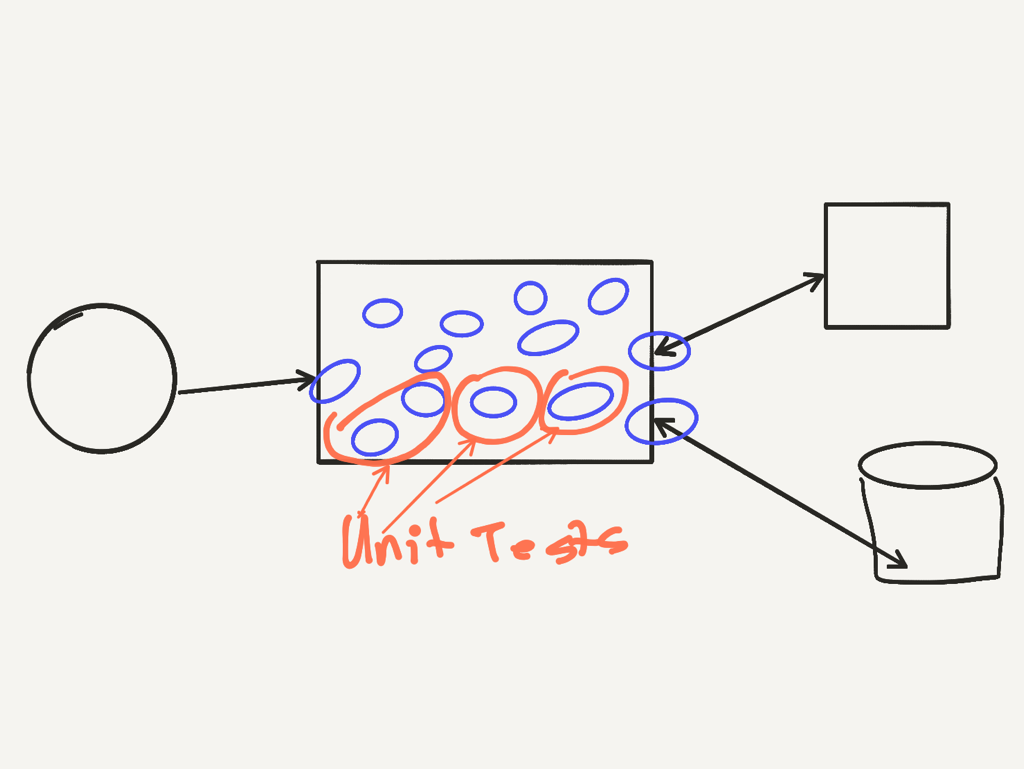
Unit tests, test a unit of code. What is a unit of code? A class, a method? A couple of collaborating classes? If it’s a class do we test every method of a class?
A unit of code encapsulates behaviour and data. In unit testing we focus on testing behaviour. Not the implementation details. The Single Responsibility Principle (SRP) states;
“Every module or class should have responsibility over a single part of the functionality provided by the software, and that responsibility should be entirely encapsulated by the class.”
If we follow SRP, then the unit of code under test, will have only one method (or two) as an entry point. The entry point provides access to the behaviour encapsulated by the unit of code. Unit tests exercise these. The test asserts that the encapsulated behaviour is correct.
We assert this in two ways. First, by asserting against the data returned. Second, by asserting against the expectations against collaborating classes.
Unit tests should run fast (in milliseconds), in the same process and in-memory. Unit tests should not have any I/O or cross any process boundaries. If they do, then they become another kind of test.
Acceptance Tests
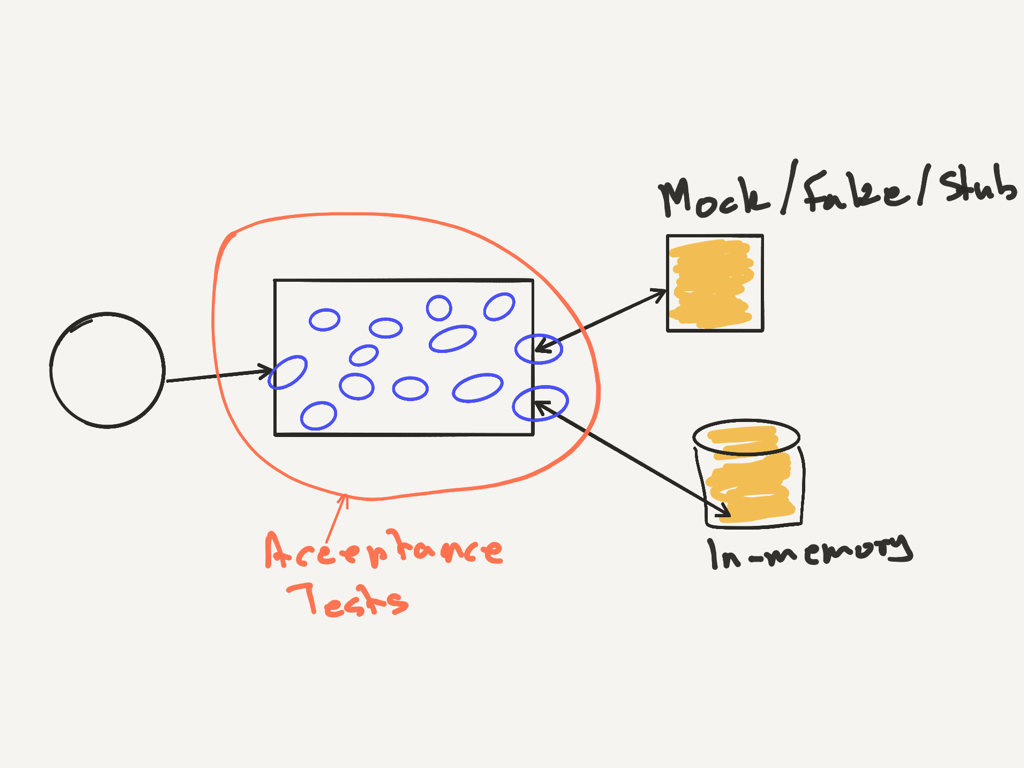
Acceptance tests, test if we are building the right thing. We write these tests in terms that our business and users can understand. With these tests we focus on only our code and the system we build. We mock out all the external dependencies. If we can’t mock these out, we try to create local, in-memory or implementations that we can control.
For example if our system relies on a database, we hook it up to a lightweight version we can spin up in a container. An in memory version works even better (SQL-Lite, SQL Server Local edition). We can start our lightweight database from a clean, known state for our tests. We can throw away the database after running tests, as no one else relies on it.
Integration Tests
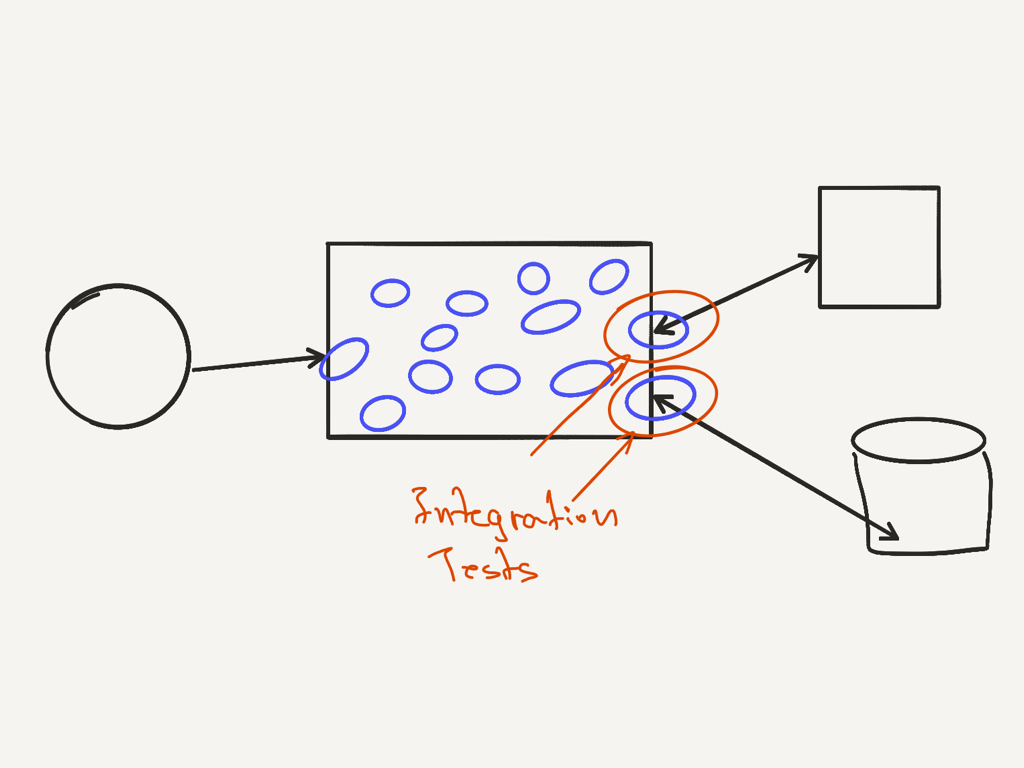
Integration tests, test the code that integrates with other systems. This can be APIs built by another team, a database, a 3rd party integration. Anything that is outside of the code we own. Integration tests, test the boundaries of our code and the integration. These are different from end to end tests.
Monitoring and Alerts
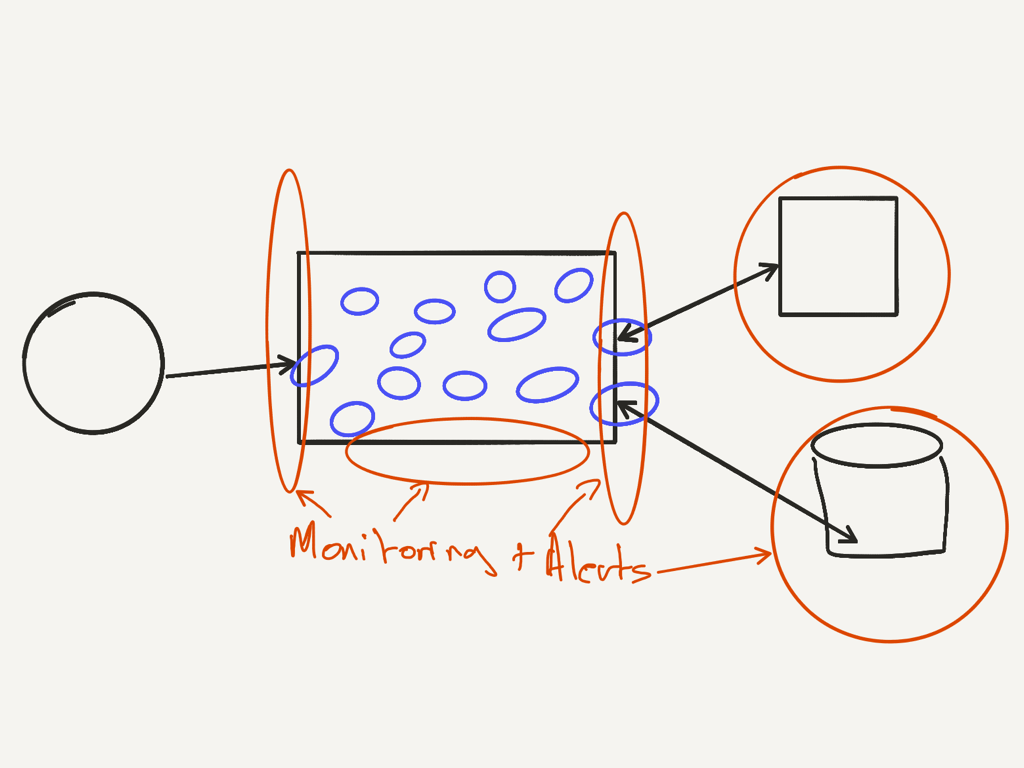
Monitoring is based on things we know that could go wrong and have gone wrong in the past. The monitoring and alerting framework raises an alert when things go wrong with the production system.
I’ve included Monitoring and Alerting here because, we should know when something is broken and why it’s broken. We should be alerted when something is already broken or is about to break. This shouldn’t be done as an after thought. We should test or alerts even in test environments. Consider adding alerts to the walking skeleton.
Monitoring can be thought of as the outer loop of TDD.
Smoke Tests
Smoke tests are a finger-in-the-air check whether the system is working. They test a happy path, or a critical path through the system. We should have only a few of these.
Smoke tests aren’t intrusive. They aren’t exhaustive either. Focus on critical user journeys. Run them on production environments. We write smoke tests very early, when we build a walking skeleton of the system.
Manual Tests
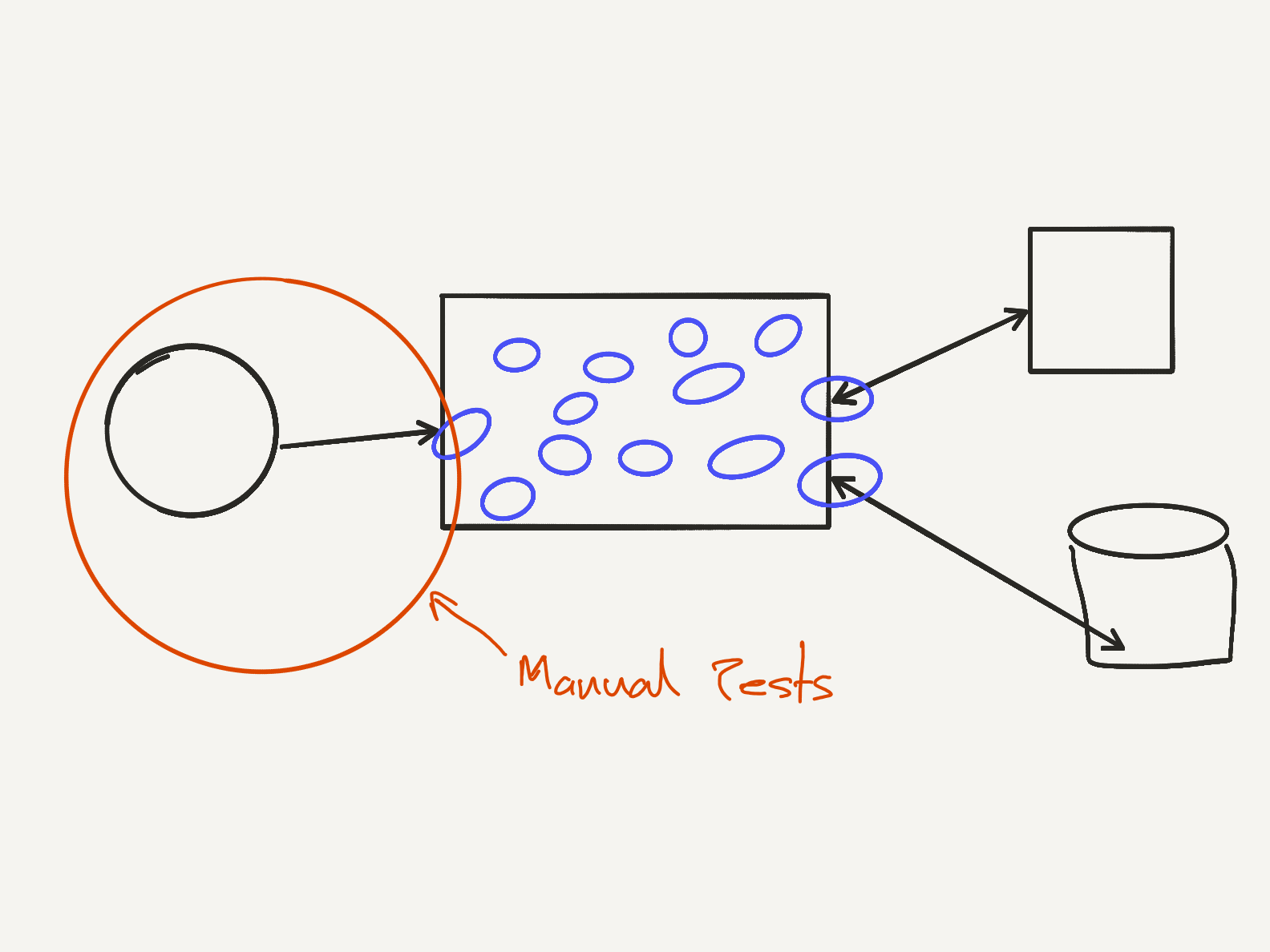 Manual tests are driven by a tester or a user. They are human driven. A tester interacts with the system as a user. Manual tests are costly, but valuable. Manual tests are the most expensive kind of tests, both in terms of money and effort. So we need to get the most value out of them.
Manual tests are driven by a tester or a user. They are human driven. A tester interacts with the system as a user. Manual tests are costly, but valuable. Manual tests are the most expensive kind of tests, both in terms of money and effort. So we need to get the most value out of them.
Manual tests are valuable when they are exploratory tests. This is where we leverage the mindset of people who can break the system.
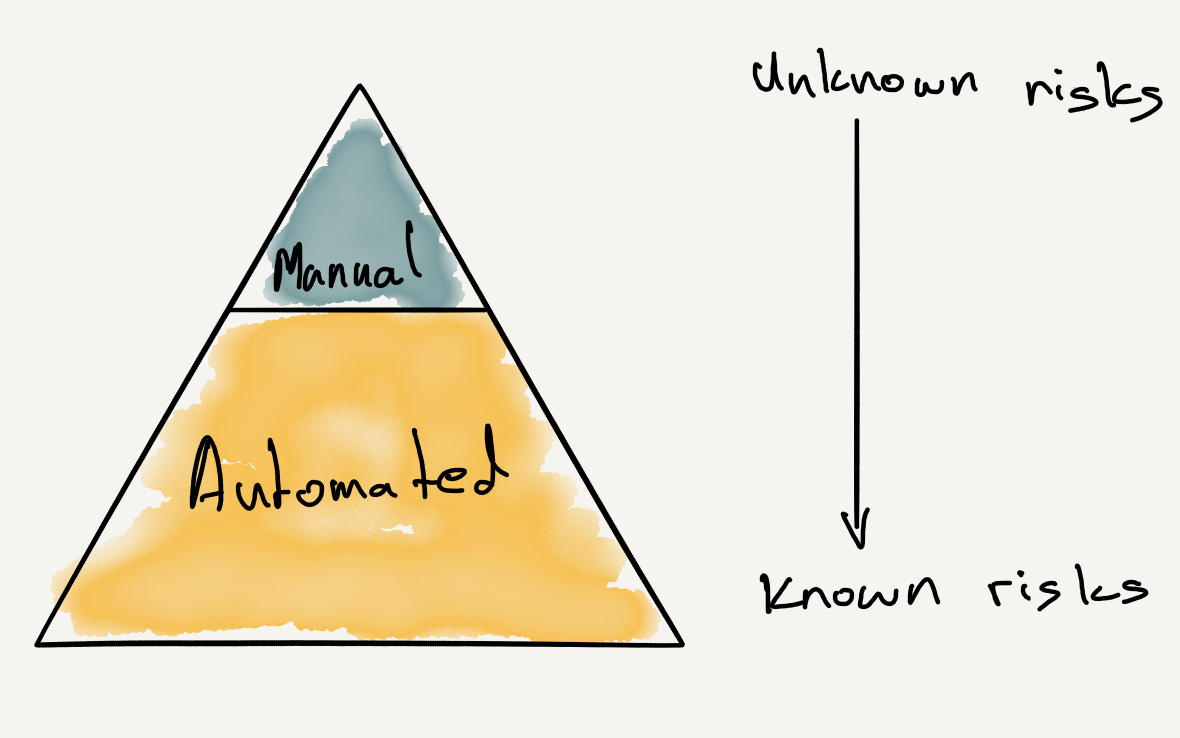
Manual tests explore the unknown. These tests look at the new capabilities of the system. They look at how users interact with the system in the wild. It’s a process of converting the unknown unknowns into known knowns. We can only automate against expected states we know.
The Anti-Patterns and their effects
Over-reliance on end to end (E2E) tests
End to end tests are an all-embracing simulation of real user scenarios. An over-abundance of these tests are a symptom of testing as an after thought. The myth is that this is where we get more value. E2E tests have value for very simple systems.
As the system grows, there are more scenarios to test. The system grows in complexity. E2E tests reflect that complexity. The tests become increasingly fragile and take more time and effort to maintain. Investing this time and effort on unit tests is a better strategy.
E2E tests depend on all of the moving parts of a complex system being in the right state. The dependencies have to work perfectly. If another team breaks a dependent service, our tests will break. This makes E2E tests inherently fragile.
The only place we can get value out of E2E tests is in production, but then we are better off relying on our monitoring and alerts.
Say no to More E2E Tests
Manual tests for each release
Manual tests before each release is release management theatre. This is wasteful. This anti-pattern is the cause most frequently seen bottleneck to getting software delivered fast.
Tests before a release should be automated regression tests. If tests have passed earlier in the pipeline and we have confidence in them, then we shouldn’t need to test each release manually.
Automated tests are the responsibility of the Automation QAs/Testers
When technology organisations start to do automated testing, the first thing they do is to recruit Automation Testers. This feeds the previous anti-pattern.
I’ve seen test code rot due to the lack of maintenance, because they are owned by the “Automation QAs”. No one fixes the slow or flaky tests. Eventually the build is red all the time, and someone turns off the tests, saying “Automated testing doesn’t work for us”.

Writing automated tests is a developer responsibility. Write the tests that prove the code works.
When someone else writes the automated tests the developer doesn’t get feedback from the system they are building. The act of writing the automated test, gives the developer feedback on how the system behaves in production. This feedback can be used to change the architecture of the system.
Flaky tests can be fixed, as they could point to a bug or to scalability constraint. A developer can bring in software engineering skills into the test codebase and refactoring the test code to make it more readable.
Automated tests, that haven’t been written by a developer, tend to be a copy, pasted nightmare with scattered timeouts.
Summary
It’s important that we get the balance between different types of tests right. We use our tests to give us early feedback.
This is crucial, as we want to fail fast. When we rely on the wrong type of tests, feedback is delayed, or not present at all. Fast feedback is key to mitigating the inherent risk in the complex system we build. Without it we are building software blind.
Notes
- A more detailed treatment of the testing pyramid. The Practical Test Pyramid by Ham Vocke
- I also like the Small, Medium and Large nomenclature for tests by Simon Stewart
- A dissection of a dissection of the test driven development process by Adrian Colyer, in the Morning Paper
03 Dec 2017
It’s that time of the year. The inboxes are full with party invites from HR, the successful raising of £143.40 for Movember and the numerous out of office notifications from those who have the temerity to escape to warmer climes.
Amongst all those e-mails, just when you think you can archive it all in one swoop, is one with the expected yet, ominous title “Christmas Release Freeze”.

This marks the time of the year, when all the good practices followed the rest of the year are thrown out with wild abandon. The meeting invites go out for the “Daily Release CAB Meeting” set for 10:30 am everyday for the rest of December, until January when everyone has sobered up and the New Year’s resolutions kick in.
It’s the time of the year when middle managers test the boundaries of the Peter Principle, whilst the higher ups are away.
It’s the time of the year when the delivery pipeline freezes as the central heating pipes warm up. Nowhere does the Agile manifesto or the Continuous Delivery book say, “Applicable between November 30th and January 8th”.
The reality of a release freeze
However, the reality is that even during a release freeze, releases still happen, but with more release management theatre. The daily CAB meetings are spent arguing why one release is more important than the other and should break the rules.
Woe to the developer who intends to use the downtime to read the Continuous Delivery book. A manager comes over with a bounce in his step, asking to see if the feature that everyone ignored for the rest of the year, can be built in the spare time suddenly available because of the release freeze.
I’ve never observed a successful release freeze, that had zero releases during the release freeze period. The release cadence has always been similar to the rest of year but with the extra friction of pointless meetings.
The argument made for release or change freezes is to maintain stability, whilst having only a skeleton crew to deal with any issues. The holiday period is when organisations see their largest transaction volumes for the whole year. The need for stability is valid one.
What are the alternatives?
A business powered by technology doesn’t stop whilst the release freeze is in place. Why should we freeze the change of the technology that powers the business?
Let’s look at a few methods to overcome the madness that is a release freeze
Slowdown instead of freezing
Instead of coming to a complete stop, slow down the pace of work. If you’ve been continuously delivering change the rest of the year, at a faster pace, then it should easy to slow down.
Doing work in smaller batch sizes allows you to be reactive quickly. They also have less risk, and it’s easier to assess the risk of a small change upsetting the stability of a system.
Smaller items can be released by a skeleton team, in a serial manner. It gives them time to focus on the work, without the extra noise that is present around a team the rest of the year. Anecdotally, I’ve seen that teams can be more productive during the holiday period.
The hard truth is that, many organisations find it hard to slow down. The software delivery process is optimised for large pieces of work and big bang releases, thus hiding inefficiencies. Release management theatre does need a large audience!
Prioritise stability and resilience
If you care about stability, you should care about it the whole year and not just during the last month of the year. Work on resilience. A resilient system and process will scale up and down according to the demand placed on it.
To help with building resilience, add good alerting and monitoring to the applications you build. This helps a skeleton team during the holiday period deal with any unexpected issues without having to rely on someone who is away on holiday.
Don’t start new work
Avoid the temptation to use the newly found free time to start working on major features. This causes more risk to be piled up waiting to be released, and potentially blow up when the release freeze is lifted. Some developers can be overly bold and daring after the office Christmas party drinks and implement major features. Only to have very little recollection of what was done the next year.
Management tends to have the temptation to take advantage of large transaction volumes. If you intend to do this. Plan for it, and do the change earlier and have it ready before the release freeze. Avoid rushing in quick hacks. They will haunt the system for many years.
Accept the release freeze
Finally, you can always accept there is a release freeze. It provides precious slack time for learning. Use the time to do code katas and encourage the them team to use the quiet uninterrupted time to read, tinker and play with technology (as long as it’s not with a system in production). The learning helps the organisation build a better system next year.
The slack time gives a mental reprieve from the fast pace during the rest of the year. It will help them recharge, and bring in fresh ideas. Long lasting change happens during slack time.
Adopting Continuous Delivery practices helps to build a system and delivery process that can scale up or down according to the needs of the business, which the technology powers. Smaller pieces of work have less risk than larger pieces of work. During the rest of the year the organisation can deliver smaller pieces of work at a faster pace, and still keep delivering with little risk during a critical part of the year.
Happy Holidays!!
13 Nov 2017
It’s very easy to run terraform from a laptop and go wild managing your infrastructure. But what do you do when you start working on more complex infrastructure. How do you avoid running into each other ?
This is not about scaling infrastructure, but about scaling working practices and architecture so that you can support a large landscape of teams and applications.
More importantly, how do you scale the workflow to support working with more of your team and other teams. This is a model used in a recent project for a large organisation to support ~200 developers in multiple teams.
Nicki Watt coined the term “Terraservices” at HashiDays London 2017. This view of Terraform modules is key to scaling.
Terraservices
A Terraservice is an opinionated Terraform module that provides an architectural building block. A Terraservice encapsulates how your organisation wants to build a particular component.
For example, this is a Terraservice to build a Web Application Service on Azure.
module "frontend" {
source = "git::github.com/contino/module-webapp?ref=master"
product = "${var.product}-frontend"
location = "${var.location}"
env = "${var.env}"
app_settings = {
REDIS_HOST = "${module.redis-cache.host_name}"
RECIPE_BACKEND_URL = "${module.recipe-backend.url}"
WEBSITE_NODE_DEFAULT_VERSION = "8.8.0"
}
}
This Terraservice encapsulates how the Web Application should be configured. Scaling parameters, logging, alerting and sane defaults are set inside the Terraservice. The Terraservice exposes an interface that doesn’t require the consumer to know too much about the details of the underlying infrastructure and is opinionated towards productivity.
In this instance, the Terraservice is consumed by an application development team, to build out their product stack.
Terraservices have their own pipelines
A Terraservice has it’s own CI/CD pipeline. The pipeline runs unit, integration and compliance tests. It can even autogenerate documentation.
The integration and compliance tests run in a sandbox environment, and spin up their own test harnesses to exercise changes the Terraservice.
At the end of the pipeline, when tests are green, the Terraservice is versioned and tagged.
This ensures that a consumer picks a specific published version or stays on master to be on the bleeding edge. Keeping master stable and use Trunk Based Development practices.
Terraservices are used to compose infrastructure in Terraform projects. The Terraform projects each have their own pipelines.
Terraform projects use remote state to share outputs, which are consumed by other Terraform projects. This is how it all flows together.
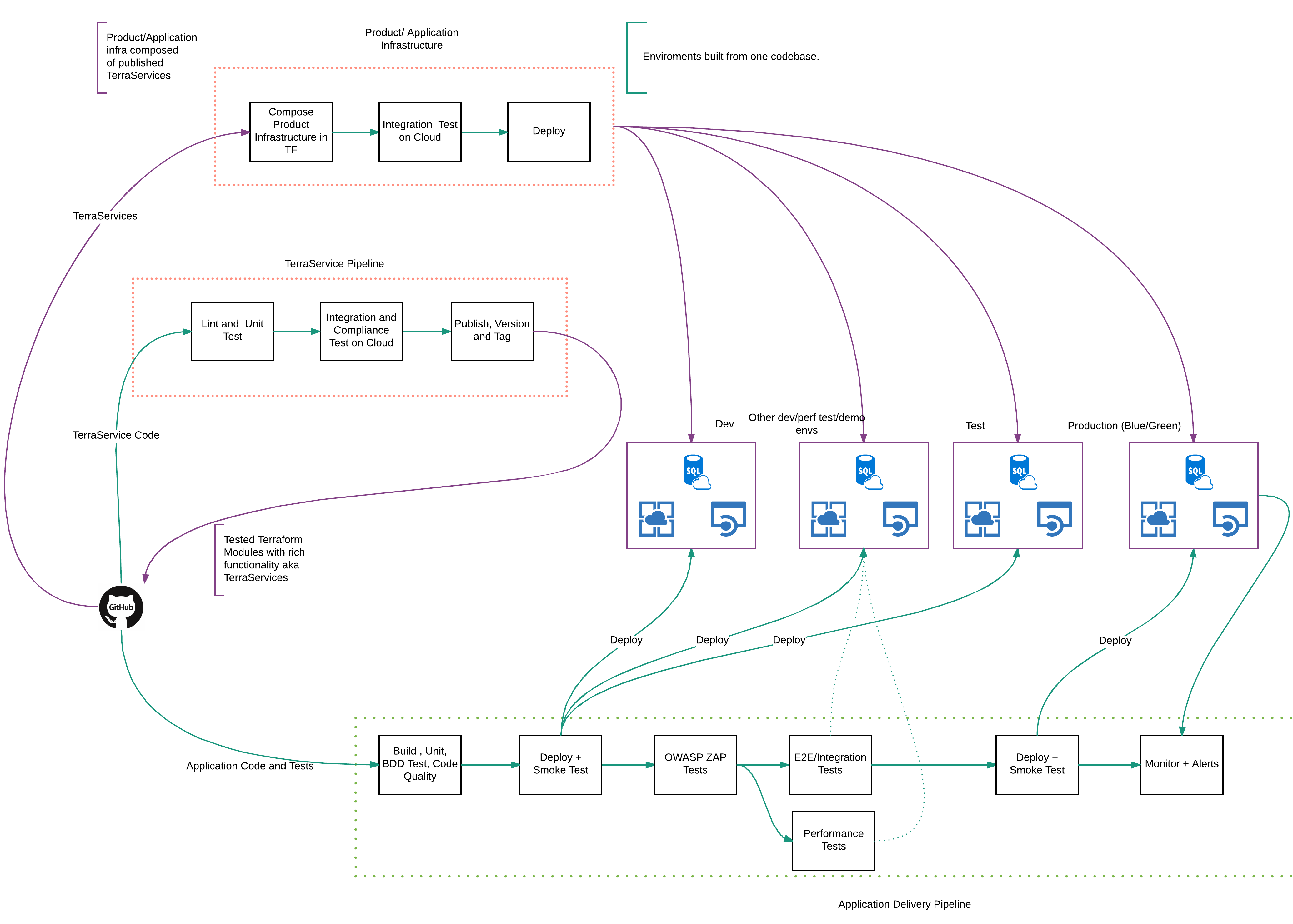
It’s the Terraform project pipelines that build actual infrastructure. They are decoupled from the application pipelines intentionally. The pipelines create empty environments that code can be deployed to. The master branch of a Terraform project reflects the current state of infrastructure. Each environment is built the same way. Environment specific variables can be tuned to change the behaviour, but once a change is committed to master, the pipelines apply the change to all environments as long as each stage in the pipeline stays green.
There can be more automated quality gates between pipeline stages but it’s important to ensure that no infrastructure used, is built manually. Building infrastructure via delivery pipelines early on, helps drive out issues that can hit your workflow later when more people work on it. An automated process is easier to improve, than a manual one.
Pick the right architecture
This is a delicate balance to achieve and there is no right answer. Pay attention to the automation pain points. Some infrastructure components can take a long time to provision. Split these out into their own Terraform projects so that they can be pre-provisioned, to be consumed by other downstream Terraform projects.
Keep core network and components that deal with core security away from Terraform projects that deal with application stacks. The application infrastructure should have dependencies on core components and use what has already been created but not be able to change it.
The infrastructure should be architected in a way that an application infrastructure can be destroyed without affecting other applications or core components.
Pick the right team structure
A crucial part of this is how the teams are organised and use Terraservices. A platform engineering team is needed to shepherd Terraservices and continuously drive the right ways of working. This team has to look across the organisational landscape and define how the Terraservices are built, ensure they help teams build their applications quickly and provide enough so that teams don’t have the need to build their own infrastructure differently.
The Terraform projects which drive the application stacks are under the control of the application teams. This means that they can iterate rapidly, and use components from an approved library of Terraservices to compose their infrastructure.
The Terraservices themselves, are maintained by a platform engineering team, but can accept pull requests from anyone in the organisation, using an internal OSS model. The role of this platform engineering team is to provide enough tooling for teams to self-serve.
Will it work for us?
This model provides a way for large organisations to allow individual product teams to build their own infrastructure, whilst providing control over how they are built.
What this doesn’t cover is, what if a team decides to use Terraform primitives instead of the available Terraservices?
This can be solved via peer reviews and the use of a Janitor monkey, which ensures that only components built the right way are allowed to exist.
In addition, Terraservices provide a happy path for teams to get up and running quickly, and are less likely to build their own.
Further reading
- Evolving Your Infrastructure with Terraform
- How to use Terraform as a team
- Terraform Recommended Practices